4. Даталогическое проектирование. Иерархическая и сетевая модели данных.
Инфологическое проектирование Ц получение семантических моделей, отражающих
информационное содержание конкретной предметной области. На этом этапе
выполняется восприятие реальной действительности, абстрагирование, изучение и
описание предметной области. В результате этого определяются объекты, свойства и
связи объектов.
Датологическое проектирование Ц организация данных, выделенных на предыдущем
этапе проектирования в форму, принятую в выбранной СУБД. Определяются внешние
ограничения по использованию СУБД.
Физический этап Ц выбор рациональной структуры хранения данных и методов доступа
к ним, исходя из арсенала методов и средств, которые предоставляются
разработчику конкретной СУБД.
Иерархическая и сетевая модели данных
(логическое проектирование)
Более ранними и основными, использовавшимися при разработке ИС на универсальных
ЭВМ, являются сетевая и иерархическая модели данных. Эти модели возникли на
основе опыта, полученного при работе с первыми системами обработки данных,
использовавших файловые структуры. На их развитие оказали существенное влияние
разработки КОДАСИЛ.
Иерархическая модель является естественной структурой для представления
информационных объектов, связанных иерархическими отношениями часть - целое, род
- вид, начальник - подчинённый. Объекты, связанные иерархическими отношениями,
образуют дерево (ориентированный связный граф), у которого одна вершина не имеет
входящих дуг (корень дерева), а все остальные вершины имеют по одной входящей
дуге. Вершины дерева - это объекты, а дуги - это иерархические связи между ними.
Тип связи в этой модели один-ко-многим (1:М).
Основные информационные единицы иерархической модели: поле (элемент данных),
сегмент (запись) и база данных. Для записей различаются: тип записи
(совокупность типов элементов данных, входящих в запись) и экземпляр записи
(значения элементов данных, входящих в запись). Для различения экземпляров
записей, относящихся к одному типу, выделяется ключ - совокупность полей записи,
значения которых позволяют идентифицировать каждый экземпляр записи данного
типа. Иерархическая структура должна удовлетворять условиям:
существует только один корневой узел, которому соответствует корневая запись;
каждый узел может быть связан с произвольным числом порождённых (подчинённых)
узлов, содержащих записи, характеризующие объект, соответствующий данному узлу;
доступ к порождённым узлам возможен только через исходный узел (существует
только один путь доступа к каждому узлу).
Полная схема иерархической БД может состоять из нескольких деревьев, порождённых
различными корневыми записями.
Корневая запись должна содержать ключ. Ключи некорневых записей должны быть
уникальны только в пределах своего уровня иерархии того дерева, которому они
принадлежат. Каждая запись идентифицируется полным сцеплённым ключом, под
которым понимается совокупность ключей всех записей, начиная с корневой, которые
образуют иерархический путь, ведущий к данной записи.
Для реализации связи типа многие-ко-многим необходимо дублирование данных, т.к.
эта связь в иерархической модели непосредственно не поддерживается. Пример:
преподаватель Ц предмет, группа Ц предмет. Один из вариантов: корневой узел Ц
группа, объекты преподаватель и предмет объединяются в порождённый узел предмет
+ преподаватель.
Сетевая модель является более общей по сравнению с иерархической структурой для
представления информационных объектов, связанных различными, в том числе и
иерархическими отношениями. Основные информационные единицы сетевой модели в
соответствии со стандартом КОДАСИЛ: элемент данных, агрегат данных, запись и
набор.
Набор реализует иерархическое отношение между типами записей двух видов - запись
одного вида это владелец набора, записи второго вида Ц члены набора.
(Функциональность связей между объектами 1:1 и 1:М является основным
ограничением целостности в моделях КОДАСИЛ.) Между записями двух типов в сетевой
модели может быть определено любое количество наборов. Это позволяет реализовать
связи типа M:N путем их представления двумя наборами, задающими связи 1:M и 1:N.
В иерархической и сетевой моделях разделяют средства описания данных (ЯОД Ц язык
описания данных) и средства манипулирования данными (ЯМД Ц язык манипулирования
данными). ЯОД содержит набор операторов для определения логической структуры и
структуры хранения БД. В частности, в сетевой модели описание состоит из трех
разделов: описание базы данных, описания записей (каждой в отдельности),
описания наборов (каждого в отдельности).
Как уже выше отмечалось, первые СУБД использовали такие структуры представления
данных, которые соответствуют графовым моделям, к которым относятся
иерархическая и сетевая модели данных. Все ранние системы не основывались на
каких-либо абстрактных моделях, которые появились позже на основе анализа и
выявления общих признаков у различных конкретных систем. В ранних системах
доступ к БД производился на уровне записей. Пользователи этих систем
осуществляли явную навигацию в БД, используя языки программирования, расширенные
функциями СУБД. Интерактивный доступ к БД поддерживался только путём создания
соответствующих прикладных программ с собственным интерфейсом.
Эти системы активно использовались в течение многих лет, были накоплены
громадные базы данных, некоторые из них используются и в наше время. Поэтому
одной из актуальных проблем информационных систем является использование таких
систем совместно с современными системами.
Дополнительно
Иерархическая модель представляется в виде древовидного графа, в котором объекты
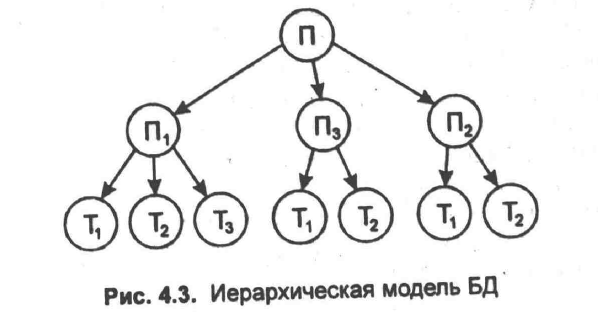
выделяются по уровням соподчиненности (иерархии) объектов (рис. 4.3).
На верхнем, первом уровне находится информация об объекнте "поставщики" (П), на
втором - о конкретных поставщиках П1, П2 и П3, на нижнем, третьем, уровне - о
товарах, которые могут поставлять конкретные поставщики. В иерархической модели
должно соблюдаться правило: каждый порожденный узел не может иметь больше одного
порождающего узла (тольнко одна входящая стрелка);
в структуре может быть только один непорожденный узел (без входящей стрелки) -
корень. Узлы, не имеющие входных стрелок, носят название листьев. Узел
интегрируется как запись. Для поиска необходимой занписи нужно двигаться от
корня к листьям, т.е. сверху вниз, что значительно упрощает доступ. Достоинство
иерархичеснкой модели данных состоит в том, что она позволяет описать их
структуру как на логическом, так и на физическом уровне. Недостатками данной
модели являются жесткая фиксированность взаимосвязей между элементами данных,
вследнствие чего любые изменения связей требуют изменения струкнтуры, а также
жесткая зависимость физической и логической организации данных. Быстрота доступа
в иерархической мондели достигнута за счет потери информационной гибкости (за
один проход по дереву невозможно, например, получить иннформацию о том, какие
поставщики поставляют, скажем, тонвар Т1). Указанные недостатки ограничивают
применение иерархической структуры.
В иерархической модели используется вид связи между эленментами данных "один ко
многим". Если применяется взаимонсвязь вида "многие ко многим", то приходят к
сетевой модели данных.
Сетевая модель базы данных для поставленной задачи преднставлена в виде
диаграммы связей (рис. 4.4). На диаграмме указаны независимые (основные) типы
данных П1, П2 и П3 т.е. информация о поставщиках, и зависимые - информация а
товарах Т1, Т2 и Т3. В сетевой модели допустимы любые виды связей между записями
и отсутствует ограничение на число обратных связей. Но должно соблюдаться одно
правило: связь включает основную и зависимую записи.
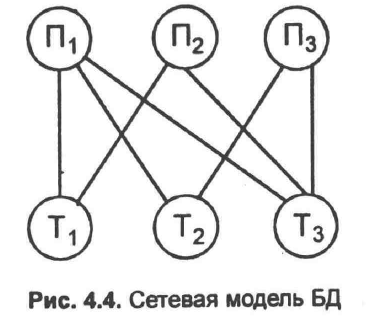
Достоинство сетевой модели БД - большая информанционная гибкость по сравнению с
иерархической моделью. Одннако сохраняется общий для обеих моделей недостаток -
достаточно жесткая структура, что препятствует развитию иннформационной базы
системы управления. При необходимоснти частой реорганизации информационной базы
(например, при использовании настраиваемых базовых информационных техннологий)
применяют наиболее совершенную модель БД - ренляционную, в которой отсутствуют
различия между объектами и взаимосвязями.